图与相关问题 这两周学习了图,和一些图相关的问题。
基本概念 图是一种非线性结构 ,与树相比,它可以是非连通的 ,也可以是有环的 ,所以图的问题要更为复杂。
图有很多术语,这里就不一一列举了,图的基本概念 - songguojun - 博客园 这篇文章写得比较全面,可以去看看。
表示方法 比较常用的有两种——邻接矩阵 表示法和邻接表 表示法。
邻接矩阵 应当明确,我们要保存一张图,实际上就是要保存它的顶点 和边 ,在不存在孤立点 时,就相当于保存所有的边 。而每两个顶点之间都可能有边 。所以我们用一个二维矩阵G[n][n]来记录边的情况。G[i][j]=true代表有一条从i指向j的边 ,将G称为邻接矩阵 。
邻接矩阵法的好处就是简单、直观,可以在O(1)的时间内检查两个顶点之间是否有边 以及对边进行增删 ,而缺点就是空间浪费很大 (尤其是对于稀疏图),且不易于增删节点 。
邻接表 邻接表 表示法,是对每一个节点记录它指向的节点 ,每个节点指向的节点数目各异 ,所以不能用静态数组 保存,在C语言中要用链表或者动态数组,而C++中则可以直接用vector ,保存为vector<vector<int>> G(n),将G称为邻接表 。
邻接表法只保存实际存在的边 ,可以大大节省空间(尤其是对稀疏图 ),不过判断边 ,删除边 的复杂度是O(N)的。
如果是稀疏图,而且没有删除边的操作时,尽量选邻接表作为储存结构。
接下来列举一些图相关的算法
图的遍历算法 首先当然是遍历。和树相同,分为深度优先遍历 和广度优先遍历 。不过,图的结构并不像树那样明朗 ,而是很复杂。比如一张图可以分为好几个连通块 ,要怎样才能恰到好处地访问每个节点呢?在图的遍历算法中,我们总是用一个vis数组 ,来记录每个节点有没有被访问,只有当它没被访问时,才访问之。从一道例题来理解遍历算法吧。
代码如下,图的遍历算法比较简单,就不多说了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <bits/stdc++.h> using namespace std;vector<vector<int >> graph; vector<bool > vis; void dfs (int node) cout << node << " " ; vis[node] = true ; for (int next : graph[node]) if (!vis[next]) dfs (next); } int main () int n, e, a, b; cin >> n >> e; graph = vector<vector<int >>(n); vis = vector <bool >(n, false ); for (int i = 0 ; i < e; ++i) { cin >> a >> b; graph[a].push_back (b); graph[b].push_back (a); } for (auto &v : graph) sort (v.begin (), v.end ()); dfs (0 ); cout << endl; vis = vector <bool >(n, false ); queue<int > q; vis[0 ] = true ; q.push (0 ); while (!q.empty ()) { int cnt = q.size (); for (int i = 0 ; i < cnt; ++i) { int node = q.front (); cout << node << " " ; q.pop (); for (int next : graph[node]) if (!vis[next]) { vis[next] = true ; q.push (next); } } } cout << endl; return 0 ; }
最大连通分量 我们可以根据连通性将一张图分为几个极大连通子图 ,这些子图之间互不连通,最大连通子图 中节点的个数叫做最大连通分量 。
求最大连通分量的过程,其实就是对整张图进行dfs 的过程。当从一点出发进行dfs,不再有可达的节点时 ,就找到了一张极大连通子图。接下来只要继续从下一个未被访问 的节点出发展开dfs即可。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <bits/stdc++.h> using namespace std;vector<vector<int >> graph; vector<bool > vis; int ans = 0 , now = 0 ;void dfs (int node) ++now; vis[node] = true ; for (int next : graph[node]) if (!vis[next]) dfs (next); } int main () int n, e, a, b; cin >> n >> e; graph = vector<vector<int >>(n); vis = vector <bool >(n, false ); for (int i = 0 ; i < e; ++i) { cin >> a >> b; graph[a].push_back (b); graph[b].push_back (a); } for (int i = 0 ; i < n; ++i) if (!vis[i]) { now = 0 ; dfs (i); ans = max (ans, now); } cout << ans << endl; return 0 ; }
最大连通分量的应用题:695. 岛屿的最大面积 - 力扣(LeetCode) ,岛屿的最大面积即最大连通分量,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public : int now=0 ,ans=0 ; void dfs (int i,int j,vector<vector<int >> &grid) { grid[i][j]=0 ; ++now; if (i<grid.size ()-1 &&grid[i+1 ][j]==1 ) dfs (i+1 ,j,grid); if (i>0 &&grid[i-1 ][j]==1 ) dfs (i-1 ,j,grid); if (j<grid[0 ].size ()-1 &&grid[i][j+1 ]==1 ) dfs (i,j+1 ,grid); if (j>0 &&grid[i][j-1 ]==1 ) dfs (i,j-1 ,grid); } int maxAreaOfIsland (vector<vector<int >>& grid) for (int i=0 ;i<grid.size ();++i) for (int j=0 ;j<grid[0 ].size ();++j) if (grid[i][j]) { now=0 ; dfs (i,j,grid); ans=max (now,ans); } return ans; } };
类似做法的题目还有200. 岛屿数量 - 力扣(LeetCode) ,1254. 统计封闭岛屿的数目 - 力扣(LeetCode) ,827. 最大人工岛 - 力扣(LeetCode)
最小生成树 一个连通图的生成树 是一个极小的连通子图 ,它包含图中全部的n个顶点 ,但只有构成一棵树的n-1条边 。如果每条边被赋予一定的权重 ,使这n-1条边的权重之和最小 的生成树叫最小生成树 。最小生成树有两种经典算法——Prim算法 和Kruskal算法 ,它们都应用了贪心 的思想。我在这里主要介绍Prim算法 。
朴素的Prim算法 Prim算法将顶点分为两类 ,已经添加 到树中的,和尚未添加 的。最开始随便添加一个节点,然后每次从已添加 的顶点向外拓展 ,找到距离当前节点集最近 的尚未添加 的节点,添加之,直到所有节点都添加了 ,或者再无可以添加的节点 (非连通,失败)。在算法中,我们维护一个lowest ,代表尚未添加的节点到树的最小距离 ,每选出一个节点,就尝试用到它的距离 更新其他节点。然后再找出最小距离的节点,作为下一个添加的节点。例题:1584. 连接所有点的最小费用 - 力扣(LeetCode) ,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution {public : int minCostConnectPoints (vector<vector<int >>& points) int n=points.size (),ans=0 ,pre=0 ; vector<int > get, vis (n),lowest (n,INT_MAX); vector<vector<pair<int , int >>> graph (n); for (int i=0 ;i<n;++i) for (int j=i+1 ;j<n;++j) { int d=abs (points[i][0 ]-points[j][0 ])+abs (points[i][1 ]-points[j][1 ]); graph[i].push_back ({j,d}); graph[j].push_back ({i,d}); } get.push_back (0 ); vis[0 ] = true ; while (get.size () < n) { int next=-1 ; for (auto &p:graph[pre]) if (!vis[p.first]&&p.second<lowest[p.first]) lowest[p.first]=p.second; for (int i=0 ;i<n;++i) if (next==-1 ||!vis[i]&&lowest[i]<lowest[next]) next=i; get.push_back (next); vis[next]=true ; ans+=lowest[next]; pre=next; } return ans; } };
朴素的prim算法时间复杂度是O(N^2)的,而堆优化版本可以将时间复杂度变为O(elogn) ,如果是稠密图,e~n^2则还不如朴素的版本,但如果是稀疏图,e~n,则优化很大了,下面来看看堆优化版本是如何实现的:
堆优化的Prim算法 考察上面的算法,发现对每个点,寻找lowest中的最小值,总是要O(N),如果用小根堆 来储存每个点的最小距离,则可以在logn的时间内维护堆,O(1)获取最小值。在算法中,我们在更新lowest时,如果能更新,说明它有成为下一个点的机会 ,则入堆。然后每次取出堆顶(真正距离最小的点)访问,并更新lowest。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution {public : int minCostConnectPoints (vector<vector<int >>& points) int n=points.size (),ans=0 ,pre=0 ; vector<int > vis (n) ,lowest (n,INT_MAX) ; vector<vector<pair<int , int >>> graph (n); priority_queue<pair<int ,int >,vector<pair<int ,int >>,greater<>> heap; for (int i=0 ;i<n;++i) for (int j=i+1 ;j<n;++j) { int d=abs (points[i][0 ]-points[j][0 ])+abs (points[i][1 ]-points[j][1 ]); graph[i].push_back ({j,d}); graph[j].push_back ({i,d}); } heap.push ({0 ,0 }); lowest[0 ]=0 ; while (!heap.empty ()) { pre=heap.top ().second; heap.pop (); if (vis[pre]) continue ; vis[pre]=true ; ans+=lowest[pre]; for (auto &p:graph[pre]) if (!vis[p.first]&&p.second<lowest[p.first]) { lowest[p.first]=p.second; heap.push ({lowest[p.first],p.first}); } } return ans; } };
在最坏的情况下,每一条边都要入堆,不过堆内元素不可能超过节点数,所以复杂度是O(elogn)的。
拓扑排序 拓扑排序 是一个有向无环图 的所有顶点的线性序列。且该序列必须满足下面两个条件:
每个顶点出现且只出现一次 。
若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面
直接看定义还是有些抽象,直接看一道拓扑排序最经典的例题 :207. 课程表 - 力扣(LeetCode)
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai , bi ] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入: numCourses = 2, prerequisites = [[1,0]]
输出: true
解释: 总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。示例 2:
输入: numCourses = 2, prerequisites = [[1,0],[0,1]]
输出: false
解释: 总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 105 0 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai , bi < numCoursesprerequisites[i] 中的所有课程对 互不相同
简而言之,每门课程都有其先修课 ,并且先修课具有传递性 ,如何安排课程学习顺序,才能修读所有的课程?这就是拓扑序 。拓扑排序的算法如下:维护每个节点的入度 ,如果入度为0,则代表可以修读,入队。每次选出队首,修读它,并将它的后俢课入度-1,为0则入队。注意,这里选用队列 并不是必须的。只要是容器就可以,栈也行。容器的选择会影响最后的序列,但它们都满足上面的条件,这也印证了拓扑序并不是唯一的 。本题代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public : bool canFinish (int numCourses, vector<vector<int >>& prerequisites) vector<vector<int >> graph (numCourses); vector<int > indgree (numCourses) ; int cnt=0 ; for (auto &v:prerequisites) { graph[v[1 ]].push_back (v[0 ]); ++indgree[v[0 ]]; } queue<int > q; for (int i=0 ;i<numCourses;++i) if (indgree[i]==0 ) q.push (i); while (!q.empty ()) { int now=q.front (); q.pop (); ++cnt; for (int i:graph[now]) { --indgree[i]; if (indgree[i]==0 ) q.push (i); } } return cnt==numCourses; } };
相似的题目还有:210. 课程表 II - 力扣(LeetCode) ,1462. 课程表 IV - 力扣(LeetCode)
关键路径 最长权重的路径 就是关键路径,所以关键路径也就是“最长路径 ”。关键路径是决定项目工期 的进度活动序列,在关键路径不变的情况下,改变其他项目的时间,对项目的结束时间 没有影响,所以优化关键路径 是缩短工期的关键。求关键路径及其长度的算法是建立在拓扑排序的基础上 的,实际上是拓扑排序+动态规划 。假设每个项目的结束时间为Time[i],则Time[i]=max{Time[pre]+pre->i},其中pre是i的直接前驱 。所以我们可以在拓扑排序的过程中计算出Time,例题:2050. 并行课程 III - 力扣(LeetCode) ,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public : int minimumTime (int n, vector<vector<int >>& relations, vector<int >& time) vector<vector<int >> graph (n+1 ); vector<int > res=time,indegree (n+1 ); for (auto &v:relations) { graph[v[0 ]].push_back (v[1 ]); ++indegree[v[1 ]]; } queue<int > q; for (int i=0 ;i<=n;++i) if (indegree[i]==0 ) q.push (i); while (!q.empty ()) { int now=q.front (); q.pop (); for (int i:graph[now]) { res[i]=max (res[i],time[i]+res[now]); --indegree[i]; if (indegree[i]==0 ) q.push (i); } } return *max_element (res.begin (),res.end ()); } };
事实上,关键路径思想(即拓扑排序+动态规划)还有很多应用,比如1857. 有向图中最大颜色值 - 力扣(LeetCode) ,就用到了拓扑排序+二维DP ,转移方程:res[i][j]=res[pre][j]+color。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution {public : int largestPathValue (string colors, vector<vector<int >>& edges) int n=colors.size (),ans=0 ,cnt=0 ; vector<vector<int >> graph (n); vector<int > indegree (n) ; vector<int [26]> res (n) ; for (auto &v:edges) { graph[v[0 ]].push_back (v[1 ]); ++indegree[v[1 ]]; } queue<int > q; for (int i=0 ;i<n;++i) if (indegree[i]==0 ) q.push (i); while (!q.empty ()) { ++cnt; int now=q.front (); q.pop (); ++res[now][colors[now]-'a' ]; ans=max (ans,res[now][colors[now]-'a' ]); for (int i:graph[now]) { for (int j=0 ;j<26 ;++j) res[i][j]=max (res[i][j],res[now][j]); --indegree[i]; if (indegree[i]==0 ) q.push (i); } } return cnt==n?ans:-1 ; } };
最短路径 任意两点间 的最短路径要比关键路径问题复杂,因为起点未必是入度为0的点,而终点也可以是任意一个,所以就用不上拓扑排序了。将求一个源点到其他各点的最短路 问题称为”单源点最短路问题 “,Dijkstra算法 是求解它的一种有效算法。
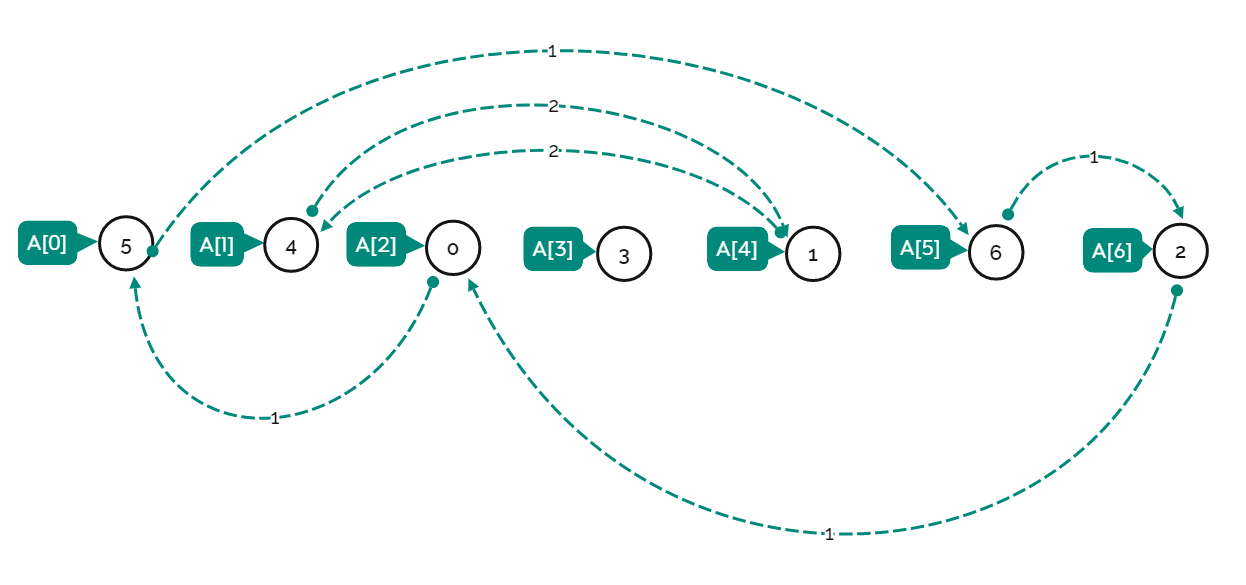
事实上,Dijkstra算法和上面求解最小生成树 问题的Prim算法极其类似(甚至复杂度都一样)。要维护的minPath与上面的lowest不同点就在于,一个是到源点的最小值,一个是到树集合的最小值,实现过程也是类似的。例题:743. 网络延迟时间 - 力扣(LeetCode) ,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public : int networkDelayTime (vector<vector<int >>& times, int n, int k) int pre=k; vector<int > minPath (n+1 ,INT_MAX) ,get,vis (n+1 ,false ) ; vector<vector<pair<int ,int >>> graph (n+1 ); for (auto &v:times) graph[v[0 ]].push_back ({v[1 ],v[2 ]}); get.push_back (k); vis[k]=true ; minPath[k]=0 ; while (get.size ()<n) { int next=0 ; for (auto &p:graph[pre]) if (!vis[p.first]&&minPath[p.first]>minPath[pre]+p.second) minPath[p.first]=minPath[pre]+p.second; for (int i=1 ;i<=n;++i) if (!vis[i]&&minPath[i]<minPath[next]) next=i; if (next==0 ) return -1 ; pre=next; get.push_back (next); vis[next]=true ; } return *max_element (minPath.begin ()+1 ,minPath.end ()); } };
同样地,Dijkstra算法也有堆优化版本 ,在稀疏图中优化是很明显的,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public : int networkDelayTime (vector<vector<int >>& times, int n, int k) vector<int > minPath (n,INT_MAX) ,vis (n,false ) ; vector<vector<pair<int ,int >>> graph (n); priority_queue<pair<int ,int >,vector<pair<int ,int >>,greater<>> heap; for (auto &v:times) graph[v[0 ]-1 ].push_back ({v[1 ]-1 ,v[2 ]}); heap.push ({0 ,k-1 }); minPath[k-1 ]=0 ; while (!heap.empty ()) { int pre=heap.top ().second; heap.pop (); if (vis[pre]) continue ; vis[pre]=true ; for (auto &p:graph[pre]) if (!vis[p.first]&&minPath[p.first]>minPath[pre]+p.second) { minPath[p.first]=minPath[pre]+p.second; heap.push ({minPath[p.first],p.first}); } } int ans=*max_element (minPath.begin (),minPath.end ()); return ans==INT_MAX?-1 :ans; } };
最短路径应用题:882. 细分图中的可到达节点 - 力扣(LeetCode) 。
结语 图的相关算法真是多,尽管上面写了不少,还是列举不完,日后见到新的算法,有时间就来补充。